
基于單細胞數據理解細胞變化過程——擬時間序列分析詳解
單細胞檢測技術的發展為我們理解復雜生命體中細胞的組成與各自功能及變化過程提供了強有力的工具。基于單細胞基因表達譜數據,我們可以窺探發育過程中細胞內的調控變化,發現腫瘤微環境中的各類細胞及它們的細胞間交流,理解器官組織中復雜多樣的細胞類型。現有單細胞研究是一個從整體到個體,再由個體特征重建整體的過程。在這個過程中,有一些非常有意思的問題是我們希望通過單細胞數據加以理解的,比如,某個組織中,某類細胞的發育生成過程;在不同條件下,細胞的改變過程和命運等等。因此,我們需要通過特定的分析手段實現對數據的分類和還原,并通過數據來勾畫出細胞間的變化過程。在這樣的背景下,擬時間序列分析(Pseudotime分析)為我們提供了來解決該問題的工具。
擬時間序列分析(Pseudotime分析)的字面意思是通過構建細胞間的變化軌跡來重塑細胞隨著時間的變化過程。從具體的分類分析和復雜程度來說,可以分為細胞軌跡分析和細胞譜系分析。
細胞軌跡分析指的是簡單模型的細胞變化軌跡分析,通常指的是細胞沿著某個過程有特定化的變化終點,軌跡具有簡單樹狀結構,一端是“根”,另一端是“葉”;細胞譜系分析通常指的是某類祖源細胞,在特定條件下,有多個發育軌跡和命運,變化過程類似復雜樹狀分支變化過程。因此,簡單細胞軌跡分析和細胞譜系分析原理上類似,復雜程度有所區別,當然,基于此的分析手法和方式也會有所不同。
近期單細胞檢測技術的發展也激起了基于單細胞數據分析技術的爆發。從現有發表研究來看,已有不同類型的分析方法用于擬時間序列分析。我們對現有常用的分析策略整理如下圖:

以下我們以Monocle軟件的擬時間分析為例,以簡單模型來了解下通過該分析我們能拿到什么樣的結果。
擬時間序列分析包括基因選擇,數據降維和在擬時間內排列細胞三個基本步驟:
1.選擇基因
推斷單細胞軌跡是一個機器學習問題。第一步是選擇機器學習方法輸入的基因。這叫做特征選擇,它對軌跡的形狀有很大的影響。算法通過檢查這些基因在細胞群中的表達模式來對細胞進行排序。尋找以“有趣”即不只是嘈雜方式變化的基因,并利用這些基因來構造數據。這些基因將產生一個健壯、準確和具有生物學意義的軌跡。
2.數據降維
一旦細胞有序排列,我們就可以在降維空間中可視化軌跡,所以首先選擇用于細胞排序的基因,然后使用反向圖嵌入算法對數據進行降維。
3.在擬時間內排列細胞
通過將表達數據投射到更低的維度空間,通過機器學習描述細胞如何從一種狀態過渡到另一種狀態的軌跡。假設軌跡具有樹狀結構,一端是“根”,另一端是“葉”。盡可能地將最佳樹與數據匹配起來。這項任務被稱為“歧管學習”,在生物過程的開始階段,細胞從根部開始,沿著主干前進,直到到達第一個分支如果有的話。然后,細胞必須選擇一條路徑,沿著樹走得越來越遠,直到到達一片葉子。一個細胞的偽時間值是它回到根的距離。
通過該過程,我們就能得到以不同分類細胞為分類的細胞軌跡圖:
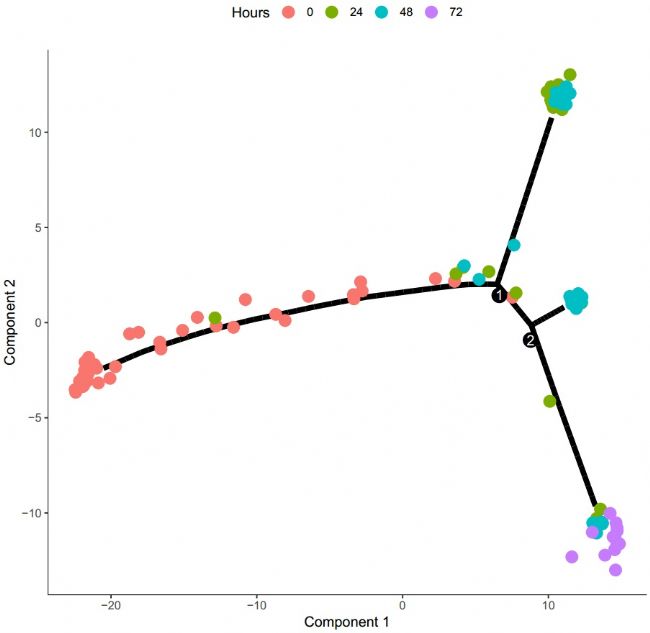
 圖4 擬時間軌跡圖
圖4 擬時間軌跡圖
得到上述擬時間軌跡圖后,我們就可以根據不同的階段分類,分別進行分類繪制,得到以下結果:
 圖5 State分類細胞軌跡圖
圖5 State分類細胞軌跡圖
 圖6 差異基因軌跡圖及非監督聚類軌跡圖
圖6 差異基因軌跡圖及非監督聚類軌跡圖
 圖7差異基因各 State 表達散點圖
圖7差異基因各 State 表達散點圖
此外,根據細胞類型分類,我們也可以將差異基因沿著擬時間軌跡繪制不同類型細胞基因表達散點圖:

圖8差異基因擬時間表達軌跡圖
 圖9 差異基因聚類熱圖
圖9 差異基因聚類熱圖
因此,通過擬時間序列分析,我們可實現構建細胞變化軌跡途徑,并能找到特征差異基因的軌跡變化過程,這將為我們深入理解不同基因在某個細胞變化過程中的重要調控作用提供依據。
以上擬時間序列分析結果圖由上海生物芯片有限公公司生物信息學專家獨立完成,如有相關需求,請聯系上海生物芯片有限公司服務平臺。
擬時間序列分析(Pseudotime分析)的字面意思是通過構建細胞間的變化軌跡來重塑細胞隨著時間的變化過程。從具體的分類分析和復雜程度來說,可以分為細胞軌跡分析和細胞譜系分析。
細胞軌跡分析指的是簡單模型的細胞變化軌跡分析,通常指的是細胞沿著某個過程有特定化的變化終點,軌跡具有簡單樹狀結構,一端是“根”,另一端是“葉”;細胞譜系分析通常指的是某類祖源細胞,在特定條件下,有多個發育軌跡和命運,變化過程類似復雜樹狀分支變化過程。因此,簡單細胞軌跡分析和細胞譜系分析原理上類似,復雜程度有所區別,當然,基于此的分析手法和方式也會有所不同。
近期單細胞檢測技術的發展也激起了基于單細胞數據分析技術的爆發。從現有發表研究來看,已有不同類型的分析方法用于擬時間序列分析。我們對現有常用的分析策略整理如下圖:
圖1 單細胞擬時間序列分析不同策略與流程
以下我們以Monocle軟件的擬時間分析為例,以簡單模型來了解下通過該分析我們能拿到什么樣的結果。
擬時間序列分析包括基因選擇,數據降維和在擬時間內排列細胞三個基本步驟:
1.選擇基因
推斷單細胞軌跡是一個機器學習問題。第一步是選擇機器學習方法輸入的基因。這叫做特征選擇,它對軌跡的形狀有很大的影響。算法通過檢查這些基因在細胞群中的表達模式來對細胞進行排序。尋找以“有趣”即不只是嘈雜方式變化的基因,并利用這些基因來構造數據。這些基因將產生一個健壯、準確和具有生物學意義的軌跡。
2.數據降維
一旦細胞有序排列,我們就可以在降維空間中可視化軌跡,所以首先選擇用于細胞排序的基因,然后使用反向圖嵌入算法對數據進行降維。
3.在擬時間內排列細胞
通過將表達數據投射到更低的維度空間,通過機器學習描述細胞如何從一種狀態過渡到另一種狀態的軌跡。假設軌跡具有樹狀結構,一端是“根”,另一端是“葉”。盡可能地將最佳樹與數據匹配起來。這項任務被稱為“歧管學習”,在生物過程的開始階段,細胞從根部開始,沿著主干前進,直到到達第一個分支如果有的話。然后,細胞必須選擇一條路徑,沿著樹走得越來越遠,直到到達一片葉子。一個細胞的偽時間值是它回到根的距離。
通過該過程,我們就能得到以不同分類細胞為分類的細胞軌跡圖:
圖2 細胞軌跡圖
從上述的軌跡圖中,我們基本可以把這些細胞的軌跡途徑分為5個不同的階段(State),因此,可以用階段(State)對軌跡圖進行繪制,以明確軌跡過程階段:

圖3 細胞軌跡圖(按階段分類)
當然,通過以上的分析結果,我們無法判斷出來軌跡的開始,因此無法確定軌跡路線。所以,我們需要結合已有認知,通過函數識別包含時間為零的大多數細胞的狀態,繪制擬時間軌跡圖:
圖4 擬時間軌跡圖得到上述擬時間軌跡圖后,我們就可以根據不同的階段分類,分別進行分類繪制,得到以下結果:
圖5 State分類細胞軌跡圖有了基本軌跡圖之后,我們可以用細胞差異基因排序得到的軌跡進行驗證。可以看到,差異基因排序產生的軌跡與以非監督方法得到的軌跡非常相似,但它更“干凈一些”。
圖6 差異基因軌跡圖及非監督聚類軌跡圖接下來,根據不同細胞狀態,把不同的基因沿著不同的State分類進行作圖,以展示基因變化過程。
圖7差異基因各 State 表達散點圖此外,根據細胞類型分類,我們也可以將差異基因沿著擬時間軌跡繪制不同類型細胞基因表達散點圖:
圖8差異基因擬時間表達軌跡圖
最后,根據擬時間序列軌跡,我們把特征差異基因表達變化進行聚類,以熱圖形式展示基因的變化過程:
圖9 差異基因聚類熱圖因此,通過擬時間序列分析,我們可實現構建細胞變化軌跡途徑,并能找到特征差異基因的軌跡變化過程,這將為我們深入理解不同基因在某個細胞變化過程中的重要調控作用提供依據。
以上擬時間序列分析結果圖由上海生物芯片有限公公司生物信息學專家獨立完成,如有相關需求,請聯系上海生物芯片有限公司服務平臺。




Copyright(C) 1998-2025 生物器材網 電話:021-64166852;13621656896 E-mail:info@bio-equip.com