
生物學家的機器學習基本術語和基本流程介紹
在生命科學領域,生物學研究與機器學習的融合正成為推動科學拓展的關鍵力量。面對海量的生物數據,傳統方法往往顯得力不從心。而機器學習技術,以其卓越的數據分析能力和模式識別優勢,極大地提高了數據處理的效率,為生物學研究帶來革命性的變化。本系列將分期介紹機器學習的定義、執行流程、關鍵概念術語和各種學習模型,包括傳統模型與神經網絡模型,幫助各位老師使用這種工具來挖掘生物學新發現。
01 什么是機器學習?
機器學習和人類認識事物的學習過程有相似之處。人類通過觀察周圍的世界并學會預測接下來可能發生的事情來理解這個世界。比如,一個孩子學習接球時,通常不了解支配球運動的物理定律。但是,通過觀察和嘗試,孩子逐漸調整對球運動的理解和身體的動作,最終能夠可靠地接住球。換句話說,孩子通過構建一個足夠準確的“模型”來學習接球,這個模型是通過對數據的反復測試和修正而建立的。
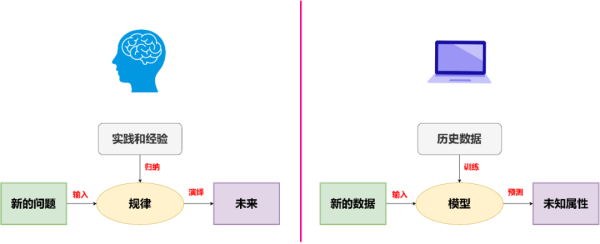
圖1.人類學習vs機器學習
機器學習是一種通過擬合預測模型或識別數據中的模式來處理數據的技術。它試圖模仿人類認識新事物的能力,但以一種客觀的方式,利用計算實現。當數據集太大或太復雜,無法通過人工分析時,或者當需要自動化數據分析過程以提高效率時,機器學習特別有用。生物實驗數據通常具有這些特點,因此機器學習在生物學研究中變得越來越重要。
在生物學研究中使用機器學習,一般有兩個主要目標:
1)準確預測:在缺乏實驗數據時,通過機器學習做出準確預測,指導未來的科研工作;
2)理解生物過程:利用機器學習深入理解生物現象。
02 機器學習的基本術語
我們首先介紹機器學習中的基本術語,并通過生物學中的例子來說明這些概念。
1.數據集
由多個數據點或實例組成,每個數據點可以看作是一個實驗的單次觀測。
2.特征
每個數據點由固定數量的特征描述,例如長度、時間、濃度和基因表達水平。
3.機器學習任務
是對我們希望機器學習模型完成的目標的明確定義。例如,在研究基因隨時間變化的實驗中,我們希望預測特定代謝物轉化為另一種物質的速率。在這種情況下,“基因表達水平”和“時間”可以稱為輸入特征,而“轉化率”則是模型的輸出,即我們感興趣的預測值。模型可以有任意數量的輸入和輸出特征。特征可以是連續的(連續數值)或分類的(離散值),分類特征通常是二元的,要么為真(1),要么為假(0)。
03 機器學習的基本流程
訓練機器學習模型時一般應采取以下步驟。首先,在接觸任何機器學習模型和代碼之前,研究者應該是完全理解手頭的數據(輸入)和預測任務(輸出)。這意味著研究者對研究問題有深入的生物學理解,比如了解數據的來源和噪聲源,并對如何根據生物學原理從輸入理論上預測輸出有一個概念。舉例說明,如果任務是推斷不同的氨基酸可能對特定的蛋白質二級結構有偏好,那么從蛋白質序列中每個位置的氨基酸頻率來預測二級結構是有道理的。此外,研究者還需要知道輸入和輸出是如何在計算機存儲的。它們是否被歸一化以防止某一特征對預測產生過大的影響?它們是被編碼為二進制變量還是連續變量?是否存在重復條目?是否有缺失的數據元素?
接下來,數據應該被分割以允許訓練、驗證和測試。訓練集用于直接更新正在訓練的模型參數。驗證集通常占可用數據的約10%,用于監控訓練、選擇超參數并防止模型過度擬合訓練數據。驗證時通常使用k倍交叉驗證方法:訓練集被分成k個大小相等的部分(例如,5或10個部分),形成k個不同的訓練和驗證集,然后在每個部分之間比較性能以選擇最佳超參數。測試集,有時稱為“保留集”,通常也占可用數據的約10%,用于評估模型在未用于訓練或驗證的數據上的表現(即估計其預期的實際表現)。測試集應在研究的最后階段或盡可能少地使用,以避免將模型調優到適應測試集。
下一步是模型選擇,這取決于數據的性質和預測任務。研究者按照所用軟件框架的最佳實踐,使用訓練集來訓練模型。大多數方法都有幾個需要調優的超參數以達到最佳性能。這可以通過隨機搜索或網格搜索完成,并可以與上述的k倍交叉驗證結合使用。此外,研究者應考慮模型集成,即將多個相似模型的輸出簡單平均,以提供一種相對可靠的方式來提高建模任務的整體準確性。最后,在測試集上評估模型的準確性。
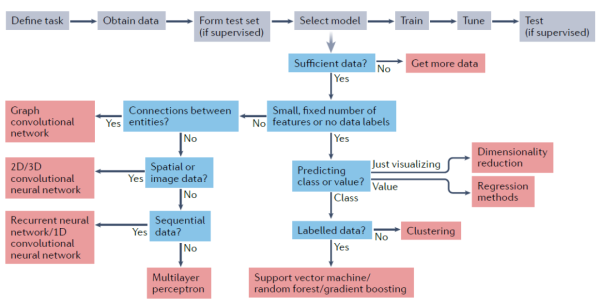
圖2.選擇并訓練機器學習方法的總體流程
本文詳細介紹了什么是機器學習,機器學習的基本術語和基本流程。在后續的文章中,小編將詳細介紹機器學習領域的重要概念術語和各種模型算法,敬請期待。



