
DeepSearch——基于深度學習的高靈敏串聯質譜數據搜庫分析策略
在基于質譜(MS)的蛋白質組學中,肽段鑒定是關鍵挑戰。傳統數據庫搜索方法依賴啟發式評分函數,存在對某些肽段組成的偏差,需引入統計估計提高鑒定率。深度學習雖提升了肽段從頭測序的準確性,但現有方法在處理不同蛋白質組成數據集及鑒定可變翻譯后修飾(PTM)方面仍存在不足。
為應對以上問題,Yonghan Yu和李明教授(Bioinformatics Solution Inc.創始人、加拿大皇家學會院士)在Nature Machine Intelligence(IF 18.8)發表了題為“Towards highly sensitive deep learning-based end-to-end database search for tandem mass spectrometry”的最新研究成果,提出了一種新的串聯質譜數據庫搜索方法—DeepSearch。在對比學習框架下,DeepSearch采用了改進的基于Transformer 的編解碼器架構。與傳統的離子與離子匹配方法不同,DeepSearch 采用數據驅動的方法對肽段-譜圖匹配進行評分,顯著降低了評分偏差,并且支持零樣本變量的可變翻譯后修飾(PTM)鑒定。DeepSearch在各種數據集上均表現出較高的準確性和穩定性,包括不同物種的數據集以及富含PTM的數據集等。DeepSearch 為串聯質譜的數據庫搜索方法提供了新的思路。
為應對以上問題,Yonghan Yu和李明教授(Bioinformatics Solution Inc.創始人、加拿大皇家學會院士)在Nature Machine Intelligence(IF 18.8)發表了題為“Towards highly sensitive deep learning-based end-to-end database search for tandem mass spectrometry”的最新研究成果,提出了一種新的串聯質譜數據庫搜索方法—DeepSearch。在對比學習框架下,DeepSearch采用了改進的基于Transformer 的編解碼器架構。與傳統的離子與離子匹配方法不同,DeepSearch 采用數據驅動的方法對肽段-譜圖匹配進行評分,顯著降低了評分偏差,并且支持零樣本變量的可變翻譯后修飾(PTM)鑒定。DeepSearch在各種數據集上均表現出較高的準確性和穩定性,包括不同物種的數據集以及富含PTM的數據集等。DeepSearch 為串聯質譜的數據庫搜索方法提供了新的思路。
DeepSearch方法
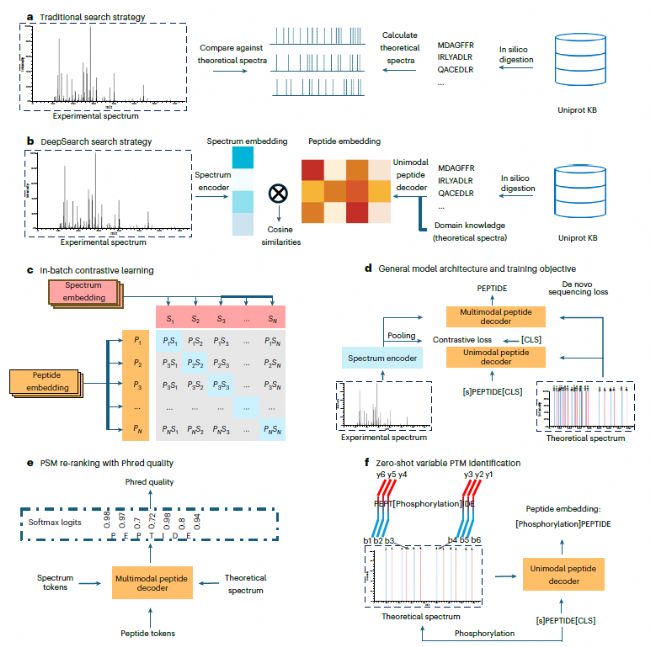
圖1 DeepSearch搜索模型
傳統的譜圖搜索策略一般是將標準參考序列通過計算機模擬酶切(in-silico digestion)后,生成對應的理論譜,然后與實際采集的譜圖進行匹配。因此,對于復雜譜圖來說,就存在一些局限性。
DeepSearch采用改進的基于Transformer的編解碼器架構,從蛋白質數據庫的計算機理論酶解開始,DeepSearch將酶解的肽和實驗MS/ MS譜圖編碼到嵌入中。DeepSearch不依賴于離子間匹配的啟發式評分函數,而是使用相應嵌入之間的余弦相似性來對PSM進行評分,這可以通過單個矩陣乘法有效地計算出來。
為了解決在 PSM 中注釋密切相關的負對的挑戰,并減少注釋中采用的搜索引擎的偏差,DeepSearch采用了批量內對比學習框架 。在訓練過程中,DeepSearch 隨機對一批錨定肽段質量的PSM 進行采樣(正對),并將肽段-譜對(不包括采樣的 PSM)用作負對(圖 1c),通過對比學習,使正對之間的余弦相似度更高,而負對之間的余弦相似度更低。并且,DeepSearch 通過Phred分數對PSMs進行重排序,確保最終的匹配更加準確。在理論譜圖中引入修飾質量偏移(mass shift),生成包含修飾信息的肽段嵌入。通過對比學習,DeepSearch可以直接對具有不同修飾的肽段進行鑒定。
實驗結果
1. PSM 評分偏差較小
擬南芥數據集的測試結果顯示,與 MSFragger、MS- GF+和 MaxQuant 比較,DeepSearch 的評分不受肽段長度影響,對缺失片段較多的短肽段評分較低,且在不同缺失片段數量下長肽段分數分布無顯著差異。在 1% FDR 控制下,其報告的 PSM 數量與其他引擎相比具有優勢,不受統計模型影響(圖2a)。此外,目標序列匹配分數(藍色)在所有肽段長度范圍內分布均勻,表明DeepSearch的評分機制對肽段長度變化的穩定性。Decoy匹配(紅色)較低且分布較窄,說明decoy匹配分數的波動較小,質控良好。
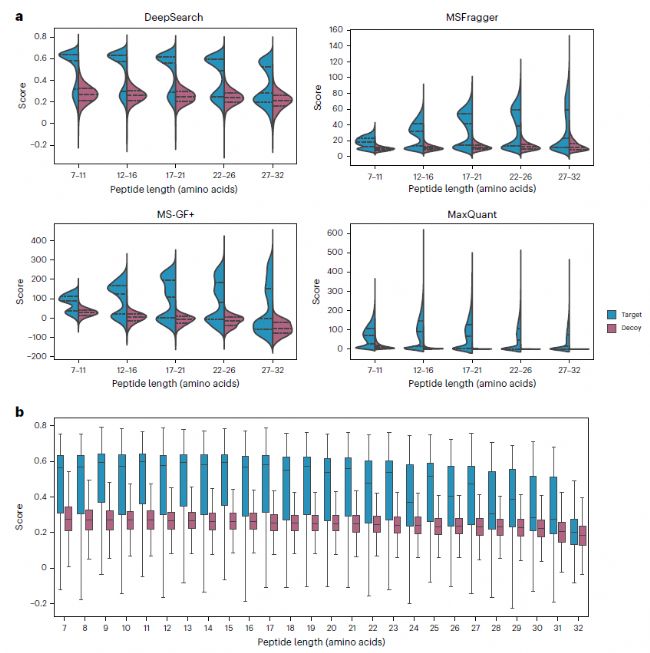 圖2 不同搜索引擎對擬南芥數據集中不同長度肽段的鑒定
圖2 不同搜索引擎對擬南芥數據集中不同長度肽段的鑒定2. 肽段鑒定準確且穩健
圖3(a–d)分別展示了擬南芥(A. thaliana)、HEK293細胞、秀麗隱桿線蟲(C. elegans)和大腸桿菌(E. coli)數據集在1%假陽性率(FDR)下的PSM數量。結果顯示DeepSearch在不依賴統計模型的情況下,仍能維持較高的PSM鑒定數量,說明對于統計估計的依賴性已顯著降低。
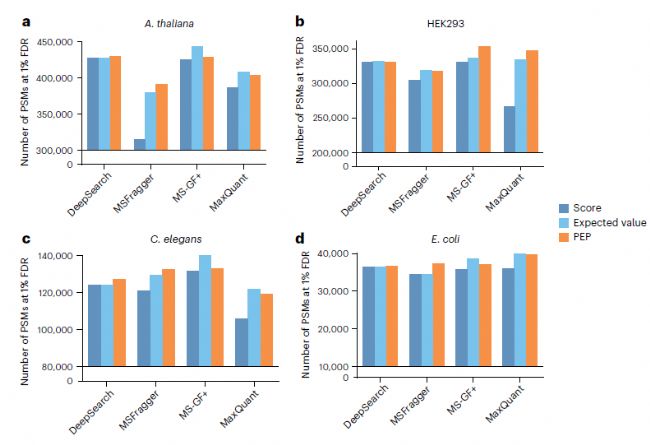 圖3 不同物種數據集通過FDR 1%質控的PSM數量
圖3 不同物種數據集通過FDR 1%質控的PSM數量3. 零樣本可變 PTM 分析
傳統搜庫方法通常需要提前對特定翻譯后修飾(如磷酸化)的數據進行訓練,限制了未知修飾的分析與發現。而DeepSearch借助深度學習,結合譜圖與肽段序列之間的普遍規律,可以實現零樣本的翻譯后修飾訓練。從圖4 HeLa 磷酸化富集數據集的測試結果看,DeepSearch在零樣本條件下,PTM分析的表現良好。圖4a分別表示對于非修飾肽段、單位點修飾肽段、雙位點修飾肽段的評分分布,可以看出隨著修飾數量增加,目標肽段的匹配(藍色)評分分布變寬,decoy匹配的得分分布變化較小,說明雖然修飾的復雜性對target匹配影響較大,但仍能保持較好的decoy質控。與MSFragger和MS-GF+相比,DeepSearch的準確性較高,但修飾肽的鑒定數量略少一些(圖4b-d),有待進一步優化。
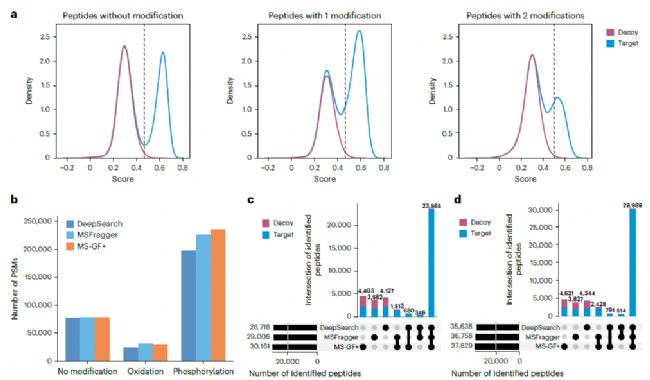
圖4 Hela磷酸化富集數據集的零樣本PTM表征
結論與展望
DeepSearch 是首個基于深度學習的端到端的串聯質譜數據庫搜索引擎,評分偏差小、準確性和穩健性高,能實現零樣本PTM分析,標志著AI技術在蛋白質組學領域的重大應用突破。未來,DeepSearch有望作為獨立引擎或重新評分模塊,整合到現有蛋白質組學分析流程中,推動蛋白質組學尤其是復雜修飾組學的快速發展。
文獻原文
Yu, Y., Li, M. Towards highly sensitive deep learning-based end-to-end database search for tandem mass spectrometry. Nat Mach Intell (2025). https://doi.org/10.1038/s42256-024-00960-1
作為生物信息學的領軍企業,BSI專注于蛋白質組學和生物藥領域,通過機器學習和先進算法提供世界領先的質譜數據分析軟件和蛋白質組學服務解決方案,以推進生物學研究和藥物發現。我們通過基于AI的計算方案,為您提供對蛋白質組學、基因組學和醫學的卓越洞見。旗下著名的PEAKS®️系列軟件在全世界擁有數千家學術和工業用戶,包括:PEAKS®️ Studio,PEAKS®️ Online,PEAKS®️ GlycanFinder, PEAKS®️ AB,DeepImmu®️ 免疫肽組發現服務和抗體綜合表征服務等。
標簽:
蛋白質組學;串聯質譜;搜庫




Copyright(C) 1998-2025 生物器材網 電話:021-64166852;13621656896 E-mail:info@bio-equip.com