Æî«∞Œª÷√ > ºº–g∑˛Ñ’ > …˙ŒÔ—–∞l(f®°)∑˛Ñ’> –æ∆¨≈c…˙ŒÔ–≈œ¢åW > 10°¡ Genomics de novoª˘“ÚΩM—–æø
 |
¿˚”√Chromium ∆Ω≈_µƒŒ¢¡˜øÿ–æ∆¨å¶Œ¢¡ø£®1ng£©ª˘“ÚΩM DNA þM––æ´¥_∑÷Ö^(q®±)£¨å¢DNA ∆¨∂Œ∑÷≈‰µΩ¥Û¡øµƒîyéßÃÿÆê–‘ barcode –Ú¡–µƒŒ¢µŒ÷–£¨√ø“ªÇÄŒ¢µŒ∂º «“ªÇÄ™ö¡¢µƒ∑¥ë™Ûwœµ£¨‘⁄Œ¢µŒ÷–Õ®þ^ PCR îU‘ˆ÷∆lj
10°¡ Genomics ŒƒéÏ£¨å¶÷∆lj∫√µƒŒƒéÏ‘⁄ Illumina úy–Ú∆Ω≈_…œúy–Ú°£Õ®þ^å¢ÅÌ◊‘Õ¨“ªÈL∆¨∂Œƒ£∞Âæþ”–œýÕ¨ barcode µƒreads þM––þB Ω”£¨ðî≥ˆ≥¨ÈL linked-reads£¨´@µ√ DNA ÈL∆¨∂Œµƒþzǘ–≈œ¢°£
|
|||||||||||||||||
| [∞l(f®°)±Ì‘u’ì] [±æÓê∆‰À˚∑˛Ñ’] [±æÓê∆‰À˚∑˛Ñ’…Ã] | ||||||||||||||||||
| ∑˛Ñ’…ã∫ ±±æ©÷Z∫Ã÷¬‘¥ø∆ººπ…∑ð”–œÞπ´Àæ | ≤Èø¥‘ìπ´ÀæÀ˘”–∑˛Ñ’ >> |
Linked-readsºº–g∫ÜΩÈ
10× Genomics π´À浃linked-reads ºº–g±æŸ|(zh®¨)…œ «¿˚”√Chromium ∆Ω≈_µƒŒ¢¡˜øÿ–æ∆¨å¶Œ¢¡ø£®1ng£©ª˘“ÚΩM DNA þM––æ´¥_∑÷Ö^(q®±)£¨å¢DNA ∆¨∂Œ∑÷≈‰µΩ¥Û¡øµƒîyéßÃÿÆê–‘ barcode –Ú¡–µƒŒ¢µŒ÷–£¨√ø“ªÇÄŒ¢µŒ∂º «“ªÇÄ™ö¡¢µƒ∑¥ë™Ûwœµ£¨‘⁄Œ¢µŒ÷–Õ®þ^ PCR îU‘ˆ÷∆lj10× Genomics ŒƒéÏ£¨å¶÷∆lj∫√µƒŒƒéÏ‘⁄ Illumina úy–Ú∆Ω≈_…œúy–Ú°£Õ®þ^å¢ÅÌ◊‘Õ¨“ªÈL∆¨∂Œƒ£∞Âæþ”–œýÕ¨ barcode µƒreads þM––þBΩ”£¨ðî≥ˆ≥¨ÈL linked-reads£¨´@µ√ DNA ÈL∆¨∂Œµƒþzǘ–≈œ¢°£
De novo assemblyπ§◊˜¡˜≥Ã
10× Genomics de novo assembly π§◊˜¡˜≥Ã∞¸¿®∏þ∑÷◊”¡øDNA ÷∆lj°¢Chromium ∆Ω≈_þM––ŒƒéÏòãΩ®°¢Illumina ∆Ω≈_úy–Ú“‘º∞ΩM—bÐõº˛þM––ΩM—bµ»þ^≥ð£
1°¢DNA ò”∆∑÷∆lj£∫øÇ¡ø≤ªµÕ”⁄2μg£ª÷˜éߥ۔⁄50Kb£¨¥Û”⁄100Kb∏¸∫√°£
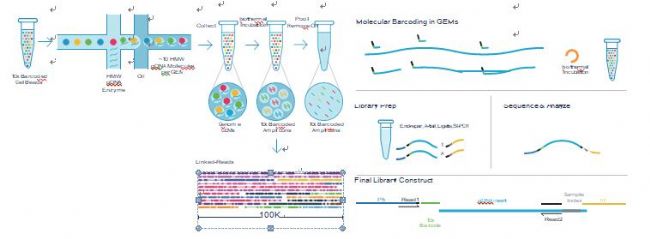
2°¢ŒƒéÏòãΩ®£∫∫¨”– barcode –≈œ¢µƒƒ˝ƒz÷ÈÕ®þ^“Îp Æ◊÷”Œ¢¡˜Ûw£¨‘⁄µ⁄“ªÇÄþBΩ”ÃéΩY∫œ DNA “‘º∞√∏µƒªÏ∫œŒÔ£¨µ⁄∂˛ÇÄþBΩ”Ãé∞¸π¸…œ”ÕµŒ–Œ≥… GEMs ≤¢þM–– ’ºØ°£ƒ˝ƒz÷È»ÐΩ‚·å∑≈∫¨”– barcode µƒ–Ú¡–£¨ÎSôC“˝ŒÔΩY∫œ‘⁄”ÕµŒ∑¥ë™ÛwœµÉ»(n®®i)ÈLÊú DNA ƒ£∞µƒÎSôCŒª÷√…œþM––PCR îU‘ˆ£¨å¢√øÇĔյŒ÷–îU‘ˆ∫Û´@µ√µƒ∫¨”– barcode –≈œ¢µƒDNA ∆¨∂ŒªÏ∫œ°£‘⁄∆¨∂Œµƒ¡Ì“ª∂ÀþBΩ” Illumina Read 2£¨ ◊Ó∫ÛÕ®þ^ò”∆∑Index PCR “˝»ÎIllumina úy–ÚP5/P7 Ω”Ó^∫Õò”∆∑index£¨ÕÍ≥…ŒƒéÏòãΩ®°£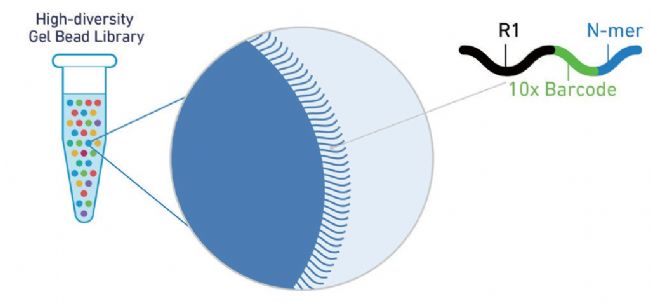
àD1 10× Genomicsƒ˝ƒz÷ȵƒÃÿ’˜
àD2 10× Genomics linked-readsŒƒéÏòãΩ®
ºº–gÉû(y®≠u)Ñð
10× Genomics de novo assembly ÉH–ËòãΩ®“ªÇÄ 10× Genomics ŒƒéÏ£¨¿˚”√Supernova™ Assembler Ðõº˛º¥ø…þM––ΩM—b£¨≤Ÿ◊˜þ^≥Ã∫ÜÜŒ£¨ΩM—b≥…±æµÕ°¢Ÿ|(zh®¨)¡ø∏þ°£
1°¢DNA–Ë«Û¡øµÕ£∫ÉH–Ë1ngª˘“ÚΩM DNA º¥ø…µ√µΩÈL∆¨∂ŒDNA ŒƒéÏ£®‘≠ ºDNA ¡ø–Ë£æ2ug£©°£
2°¢ÈLøÁ∂»–≈œ¢£∫∏˘ì˛(j®¥) barcode –≈œ¢å¢∂ýÇÄReads þM––∆¥Ω”£¨ø…´@µ√ÈLþ_100KbµƒøÁ∂»–≈œ¢°£
3°¢ΩM—b÷Ð∆⁄∂ã∫èƒò”±æ DNA ÷»°µΩΩM—bÕÍ≥…ÉH–Ë2~3÷а£
4°¢∂˛±∂ÛwΩM—b£∫10× Genomicsø…åç¨F(xi®§n)’Ê’˝µƒ∂˛±∂ÛwΩM—b£¨Ω“ æò”±æÃÿÆê–‘–Ú¡–£¨∞l(f®°)¨F(xi®§n)’Êå絃ª˘“ÚΩM–≈œ¢£¨—–æø∂˛±∂Ûwª˘“ÚΩMΩYòã°£
SupernovaΩM—b∞∏¿˝£®÷≤ŒÔ£©
ë™”√∑ΩœÚ
ÜŒÇÄÖ¢øºª˘“ÚΩMµƒòãΩ®
‘⁄“ªÇÄŒÔ∑N“—”–Ö¢øºª˘“ÚΩMµƒ«Èõrœ¬£¨å¶æþ”–÷ÿ“™–‘ÝÓµƒ‘‘≈ý∑N°¢“∞Th∑NÈ_’π10× Genomics de novo úy–Ú£¨ø…“‘øÏÀŸ´@µ√ŒÔ∑N∏þŸ|(zh®¨)¡øª˘“ÚΩM£¨Õ⁄æÚ∆∑∑NÃÿ”–ª˘“Ú£¨Ëb∂®÷ÿ“™ª˘“ÚΩYòã◊ÉÆê°£
1°¢¿±Ω∑ª˘“ÚΩM£®Horticulture Research£¨2018£©
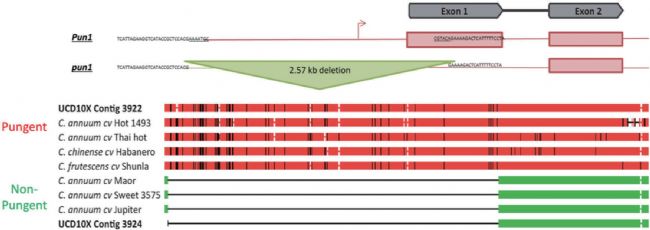
¿±Ω∑ª˘“ÚΩM «“ªÇÄ¥˙±Ì–‘µƒèÕÎs÷≤ŒÔª˘“ÚΩM£¨ª˘“ÚΩM¥Û–°þ_3.5Gb£¨∆‰÷–75%~80%ûÈ÷ÿèÕ–Ú¡–°£—–æø¿˚”√10× Genomics linked-reads ºº–g嶓ªÇÄ¿±Ω∑Îs∫œ F1 ÇÄÛwþM––úy–Ú∫ÕΩM—b£¨◊ÓΩK´@µ√µƒª˘“ÚΩM¥Û–°ûÈ3.21Gb£¨scaffold N50=3.69Mb£¨ΩM—bµ√µΩµƒ–Ú¡–‘⁄ú ¥_–‘∫ÕþB¿m(x®¥)–‘…œÉû(y®≠u)”⁄ƒø«∞À˘”–µƒ¿±Ω∑Ö¢øºª˘“ÚΩM°£Õ®þ^ phased ΩM—b∑Ω∑®£¨F(xi®§n)1 ÷–÷¨∑æı£ÞD“∆√∏ PUN1 ª˘“Ú÷– 2.5Kb µƒ≤»Î/»± ßÜŒ±∂–Õ£®¥˙±Ì¿±∫Õ≤ª¿±É…∑NÓê–Õ£©æ˘±ªÕÍ’˚µÿΩM—b≥ˆÅÌ°£∏þŸ|(zh®¨)¡øµƒ¿±Ω∑ª˘“ÚΩMΩM—b±Ì√˜ linked-reads ºº–gûȵÕ≥…±æΩM—bèÕÎs÷≤ŒÔª˘“ÚΩM“‘º∞Õ®þ^æ´¥_µƒÜŒ±∂–ÕòãΩ®±»ð^ª˘“ÚΩYòã◊ÉÆê÷π©¡À“ªÇÄÕæèΩ°£
10× Genomics π´À浃linked-reads ºº–g±æŸ|(zh®¨)…œ «¿˚”√Chromium ∆Ω≈_µƒŒ¢¡˜øÿ–æ∆¨å¶Œ¢¡ø£®1ng£©ª˘“ÚΩM DNA þM––æ´¥_∑÷Ö^(q®±)£¨å¢DNA ∆¨∂Œ∑÷≈‰µΩ¥Û¡øµƒîyéßÃÿÆê–‘ barcode –Ú¡–µƒŒ¢µŒ÷–£¨√ø“ªÇÄŒ¢µŒ∂º «“ªÇÄ™ö¡¢µƒ∑¥ë™Ûwœµ£¨‘⁄Œ¢µŒ÷–Õ®þ^ PCR îU‘ˆ÷∆lj10× Genomics ŒƒéÏ£¨å¶÷∆lj∫√µƒŒƒéÏ‘⁄ Illumina úy–Ú∆Ω≈_…œúy–Ú°£Õ®þ^å¢ÅÌ◊‘Õ¨“ªÈL∆¨∂Œƒ£∞Âæþ”–œýÕ¨ barcode µƒreads þM––þBΩ”£¨ðî≥ˆ≥¨ÈL linked-reads£¨´@µ√ DNA ÈL∆¨∂Œµƒþzǘ–≈œ¢°£
De novo assemblyπ§◊˜¡˜≥Ã
10× Genomics de novo assembly π§◊˜¡˜≥Ã∞¸¿®∏þ∑÷◊”¡øDNA ÷∆lj°¢Chromium ∆Ω≈_þM––ŒƒéÏòãΩ®°¢Illumina ∆Ω≈_úy–Ú“‘º∞ΩM—bÐõº˛þM––ΩM—bµ»þ^≥ð£
1°¢DNA ò”∆∑÷∆lj£∫øÇ¡ø≤ªµÕ”⁄2μg£ª÷˜éߥ۔⁄50Kb£¨¥Û”⁄100Kb∏¸∫√°£
2°¢ŒƒéÏòãΩ®£∫∫¨”– barcode –≈œ¢µƒƒ˝ƒz÷ÈÕ®þ^“Îp Æ◊÷”Œ¢¡˜Ûw£¨‘⁄µ⁄“ªÇÄþBΩ”ÃéΩY∫œ DNA “‘º∞√∏µƒªÏ∫œŒÔ£¨µ⁄∂˛ÇÄþBΩ”Ãé∞¸π¸…œ”ÕµŒ–Œ≥… GEMs ≤¢þM–– ’ºØ°£ƒ˝ƒz÷È»ÐΩ‚·å∑≈∫¨”– barcode µƒ–Ú¡–£¨ÎSôC“˝ŒÔΩY∫œ‘⁄”ÕµŒ∑¥ë™ÛwœµÉ»(n®®i)ÈLÊú DNA ƒ£∞µƒÎSôCŒª÷√…œþM––PCR îU‘ˆ£¨å¢√øÇĔյŒ÷–îU‘ˆ∫Û´@µ√µƒ∫¨”– barcode –≈œ¢µƒDNA ∆¨∂ŒªÏ∫œ°£‘⁄∆¨∂Œµƒ¡Ì“ª∂ÀþBΩ” Illumina Read 2£¨ ◊Ó∫ÛÕ®þ^ò”∆∑Index PCR “˝»ÎIllumina úy–ÚP5/P7 Ω”Ó^∫Õò”∆∑index£¨ÕÍ≥…ŒƒéÏòãΩ®°£
àD1 10× Genomicsƒ˝ƒz÷ȵƒÃÿ’˜
àD2 10× Genomics linked-readsŒƒéÏòãΩ®
3°¢…œôCúy–Ú£∫‘⁄ Illumina/Hiseq X ∆Ω≈_…œþM––Îpƒ©∂À150bp úy–Ú°£
4°¢De novo ΩM—b£∫¿˚”√10× Genomics µƒSupernova™ Assembler ΩM—b£¨ðî≥ˆΩYπ˚°£ºº–gÉû(y®≠u)Ñð
10× Genomics de novo assembly ÉH–ËòãΩ®“ªÇÄ 10× Genomics ŒƒéÏ£¨¿˚”√Supernova™ Assembler Ðõº˛º¥ø…þM––ΩM—b£¨≤Ÿ◊˜þ^≥Ã∫ÜÜŒ£¨ΩM—b≥…±æµÕ°¢Ÿ|(zh®¨)¡ø∏þ°£
1°¢DNA–Ë«Û¡øµÕ£∫ÉH–Ë1ngª˘“ÚΩM DNA º¥ø…µ√µΩÈL∆¨∂ŒDNA ŒƒéÏ£®‘≠ ºDNA ¡ø–Ë£æ2ug£©°£
2°¢ÈLøÁ∂»–≈œ¢£∫∏˘ì˛(j®¥) barcode –≈œ¢å¢∂ýÇÄReads þM––∆¥Ω”£¨ø…´@µ√ÈLþ_100KbµƒøÁ∂»–≈œ¢°£
3°¢ΩM—b÷Ð∆⁄∂ã∫èƒò”±æ DNA ÷»°µΩΩM—bÕÍ≥…ÉH–Ë2~3÷а£
4°¢∂˛±∂ÛwΩM—b£∫10× Genomicsø…åç¨F(xi®§n)’Ê’˝µƒ∂˛±∂ÛwΩM—b£¨Ω“ æò”±æÃÿÆê–‘–Ú¡–£¨∞l(f®°)¨F(xi®§n)’Êå絃ª˘“ÚΩM–≈œ¢£¨—–æø∂˛±∂Ûwª˘“ÚΩMΩYòã°£
SupernovaΩM—b∞∏¿˝£®÷≤ŒÔ£©
| ŒÔ∑N√˚∑Q | ∞l(f®°)±Ì∆⁄øØ | ∞l(f®°)±ÌÜŒŒª | ºº–g≤þ¬‘ | ΩM—bÐõº˛ | ΩM—bΩYπ˚ |
| ”Ò√◊B73 Maize B73 |
BMC Genomics 2018.9 |
ê€∫…»A÷ð¡¢¥ÛåW |
10×Chromium linked-reads read depth£∫45× |
supernova Assembler version 1.1.0 |
Contigs Number£∫234,153 Contig N50=14.5Kb Scaffolds Number£∫ 172,000 Scaffold N50=89Kb Total Size: 1.28Gb Genome Coverage£∫50% |
| √”◊”Panicum miliaceum |
BMC Genomics 2018.9 |
ê€∫…»A÷ð¡¢¥ÛåW |
10×Chromium linked-reads read depth£∫107× |
Supernova Assembler version 1.1.5 |
Scaffolds Number£∫30,819 Scaffold N50=912Kb Total Size: 823Mb Genome Coverage£∫83% |
| Contigs Number£∫134,573 | |||||
| ¿±Ω∑Capsicum annuum | Horticulture Research 2018.1 | º”÷ð¥ÛåW | 10×Chromium linked-reads read depth£∫56× | Supernova Assembler version 1.1 | Contig N50= 123Kb Scaffolds Number£∫83,391 Scaffold N50= 3.69Mb Total Size: 3.21Gb |
| Genome Coverage£∫ 92% | |||||
| Contigs Number£∫66825 | |||||
| “∞Th¥Û∂πGlycine latifolia | The Plant Journal 2018.4 | “¡¿˚÷Z“¡¥ÛåW | 10×Chromium linked-reads read depth£∫56× | Supernova Assembler version 1.1.5 | Contig N50=62.61kb Scaffolds Number£∫42,539 Scaffold N50=853.6 kb Total Size: 939.7Mb Genome Coverage£∫83.2% |
ë™”√∑ΩœÚ
ÜŒÇÄÖ¢øºª˘“ÚΩMµƒòãΩ®
‘⁄“ªÇÄŒÔ∑N“—”–Ö¢øºª˘“ÚΩMµƒ«Èõrœ¬£¨å¶æþ”–÷ÿ“™–‘ÝÓµƒ‘‘≈ý∑N°¢“∞Th∑NÈ_’π10× Genomics de novo úy–Ú£¨ø…“‘øÏÀŸ´@µ√ŒÔ∑N∏þŸ|(zh®¨)¡øª˘“ÚΩM£¨Õ⁄æÚ∆∑∑NÃÿ”–ª˘“Ú£¨Ëb∂®÷ÿ“™ª˘“ÚΩYòã◊ÉÆê°£
1°¢¿±Ω∑ª˘“ÚΩM£®Horticulture Research£¨2018£©
¿±Ω∑ª˘“ÚΩM «“ªÇÄ¥˙±Ì–‘µƒèÕÎs÷≤ŒÔª˘“ÚΩM£¨ª˘“ÚΩM¥Û–°þ_3.5Gb£¨∆‰÷–75%~80%ûÈ÷ÿèÕ–Ú¡–°£—–æø¿˚”√10× Genomics linked-reads ºº–g嶓ªÇÄ¿±Ω∑Îs∫œ F1 ÇÄÛwþM––úy–Ú∫ÕΩM—b£¨◊ÓΩK´@µ√µƒª˘“ÚΩM¥Û–°ûÈ3.21Gb£¨scaffold N50=3.69Mb£¨ΩM—bµ√µΩµƒ–Ú¡–‘⁄ú ¥_–‘∫ÕþB¿m(x®¥)–‘…œÉû(y®≠u)”⁄ƒø«∞À˘”–µƒ¿±Ω∑Ö¢øºª˘“ÚΩM°£Õ®þ^ phased ΩM—b∑Ω∑®£¨F(xi®§n)1 ÷–÷¨∑æı£ÞD“∆√∏ PUN1 ª˘“Ú÷– 2.5Kb µƒ≤»Î/»± ßÜŒ±∂–Õ£®¥˙±Ì¿±∫Õ≤ª¿±É…∑NÓê–Õ£©æ˘±ªÕÍ’˚µÿΩM—b≥ˆÅÌ°£∏þŸ|(zh®¨)¡øµƒ¿±Ω∑ª˘“ÚΩMΩM—b±Ì√˜ linked-reads ºº–gûȵÕ≥…±æΩM—bèÕÎs÷≤ŒÔª˘“ÚΩM“‘º∞Õ®þ^æ´¥_µƒÜŒ±∂–ÕòãΩ®±»ð^ª˘“ÚΩYòã◊ÉÆê÷π©¡À“ªÇÄÕæèΩ°£
àD3 F1÷–PUN1 ª˘“Ú2.5KbµƒPAV ±ªÕÍ»´÷ÿΩ®
2°¢¥Û∂π“∞ThΩ¸æâ∑Nª˘“ÚΩM£®Plant Journal£¨2018£©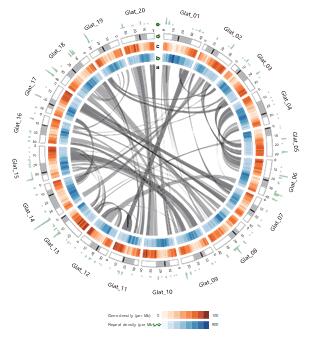
∑∫ª˘“ÚΩM—–æø
≈c≥£“é(gu®©)µƒ∂˛¥˙úy–ÚΩM—b∑Ω∞∏œý±»£¨10× Genomics de novo ÷ª–Ëð^…Ÿµƒ DNA ¡ø∫Õð^∂õƒΩM—b÷Ð∆⁄æÕø…“‘´@µ√ð^∫√µƒΩM—bΩYπ˚£¨∑«≥£þm∫œ”⁄∑∫ª˘“ÚΩM—–æø°£
17ÇÄ»À∑∫ª˘“Ú£®Nature Communications£¨2018£©
»ÀÓêÖ¢øºª˘“ÚΩM±ªèV∑∫ë™”√”⁄¨F(xi®§n)¥˙ThŒÔåW—–æø£¨»ª∂¯“ªÇÄÖ¢øºª˘“ÚΩM≤¢≤ªƒÐ¥˙±Ì»ÀÓê»∫ÛwµƒÕÍ’˚þzǘ–≈œ¢°£—–æø¿˚”√ 10× Genomics ed-reads ºº–g£¨å¶ÅÌ◊‘5ÇÄ≤ªÕ¨»À»∫µƒ17ÇÄ»À£®5ÇÄ∑«÷Þ»À°¢3Çı±√¿»À°¢4ÇÄñ|ÅÜ»À°¢3ÇÄöW÷Þ»À∫Õ2ÇăœÅÜ»À£©þM––»´ª˘“ÚΩMúy–Ú∫Õ de novoΩM—b°£‘⁄17ÇĪ˘“ÚΩM÷–Ëb∂®¡À1842ÇÄ≤ª¥Ê‘⁄”⁄Ö¢øºª˘“ÚΩM«“Œ®“ªµƒ≤»Î◊ÉÆ꣮non-reference unique insertions£¨NUIs£©£¨øÇÈLþ_2.1Mb°£∆‰÷–64%µƒNUI ‘⁄∑«»ÀÓ굃Ï`ÈLÓêª˘“ÚΩM÷–“≤”–∞l(f®°)¨F(xi®§n)£¨ «»ÀÓê◊Êœ»–Ú¡–£ª37%µƒNUI ‘⁄»ÀÓêÞD‰õΩM÷–∞l(f®°)¨F(xi®§n)£ª14% ø…ƒÐÅÌ◊‘”⁄Alu÷ÿèÕ–Ú¡–÷ÿΩMΩÈåßµƒÑh≥˝°£—–æøèä’{(di®§o)–Ë“™“ªœµ¡–∞¸∫¨≤ªÕ¨»À∑NµƒÖ¢øºª˘“ÚΩMÅÌ¿L÷∆»À»∫ÕÍ’˚µƒþzǘ∂ýò”–‘◊ÉÆêàD◊V°£
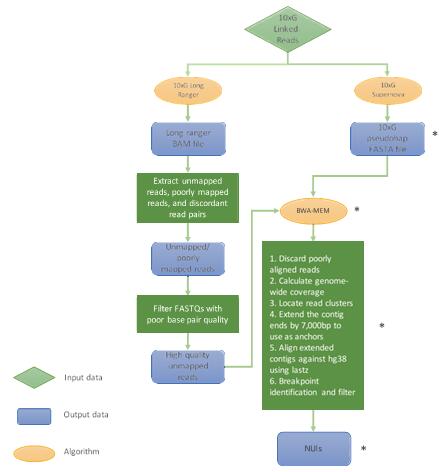
ºº–g≤þ¬‘≈cΩM—b÷∏òÀ
Ö¢øºŒƒ´I
Glycine latifolia «¥Û∂πµƒ27 ÇÄ“∞Th∂ýƒÍTh Ω¸æâ∑N÷Æ“ª£¨æþ”–‘S∂ý¥Û∂π≤ªæþljµƒþzǘ∂ýò”–‘∫ÕÉû(y®≠u)ÆêÞr(n®Æng)Àá–‘ÝÓ°£—–æø¿˚”√10× Genomics linked-reads ºº–gΩM—b¡À939MbµƒG. latifolia ª˘“ÚΩM≤ðàD°£¿˚”√þzǘàD◊V∫Õ¥Û∂πª˘“ÚΩM–Ú¡––≈œ¢£¨å¢ Scaffolds íÏðdµΩ¡À20ÇĻ慴ÛwºâÑeµƒºŸ∑÷◊”÷–°£‘⁄ΩM—bª˘“ÚΩM÷–Ëb∂®µΩ¡À304ÇÄNBS-LRR Óêøπ≤°µ∞∞◊ª˘“Ú∫Õ367ÇÄÖ¢≈cª˘µA∑¿”˘Ìëë™∫Õ∑«ThŒÔ√{∆»Ìë뙵ƒ LRR Óê ÐÛwº§√∏ª˘“Ú°£G. latifolia ª˘“ÚΩMµƒΩM—b∫Õ◊¢·åûÈ¥ŸþM¥Û∂πµƒþzǘ∏ƒ¡ºÃ·π©¡ÀåöŸFŸY‘¥°£
”“àD4 Glycine latifolia ª˘“ÚΩMΩYòã
∑∫ª˘“ÚΩM—–æø
≈c≥£“é(gu®©)µƒ∂˛¥˙úy–ÚΩM—b∑Ω∞∏œý±»£¨10× Genomics de novo ÷ª–Ëð^…Ÿµƒ DNA ¡ø∫Õð^∂õƒΩM—b÷Ð∆⁄æÕø…“‘´@µ√ð^∫√µƒΩM—bΩYπ˚£¨∑«≥£þm∫œ”⁄∑∫ª˘“ÚΩM—–æø°£
17ÇÄ»À∑∫ª˘“Ú£®Nature Communications£¨2018£©
»ÀÓêÖ¢øºª˘“ÚΩM±ªèV∑∫ë™”√”⁄¨F(xi®§n)¥˙ThŒÔåW—–æø£¨»ª∂¯“ªÇÄÖ¢øºª˘“ÚΩM≤¢≤ªƒÐ¥˙±Ì»ÀÓê»∫ÛwµƒÕÍ’˚þzǘ–≈œ¢°£—–æø¿˚”√ 10× Genomics ed-reads ºº–g£¨å¶ÅÌ◊‘5ÇÄ≤ªÕ¨»À»∫µƒ17ÇÄ»À£®5ÇÄ∑«÷Þ»À°¢3Çı±√¿»À°¢4ÇÄñ|ÅÜ»À°¢3ÇÄöW÷Þ»À∫Õ2ÇăœÅÜ»À£©þM––»´ª˘“ÚΩMúy–Ú∫Õ de novoΩM—b°£‘⁄17ÇĪ˘“ÚΩM÷–Ëb∂®¡À1842ÇÄ≤ª¥Ê‘⁄”⁄Ö¢øºª˘“ÚΩM«“Œ®“ªµƒ≤»Î◊ÉÆ꣮non-reference unique insertions£¨NUIs£©£¨øÇÈLþ_2.1Mb°£∆‰÷–64%µƒNUI ‘⁄∑«»ÀÓ굃Ï`ÈLÓêª˘“ÚΩM÷–“≤”–∞l(f®°)¨F(xi®§n)£¨ «»ÀÓê◊Êœ»–Ú¡–£ª37%µƒNUI ‘⁄»ÀÓêÞD‰õΩM÷–∞l(f®°)¨F(xi®§n)£ª14% ø…ƒÐÅÌ◊‘”⁄Alu÷ÿèÕ–Ú¡–÷ÿΩMΩÈåßµƒÑh≥˝°£—–æøèä’{(di®§o)–Ë“™“ªœµ¡–∞¸∫¨≤ªÕ¨»À∑NµƒÖ¢øºª˘“ÚΩMÅÌ¿L÷∆»À»∫ÕÍ’˚µƒþzǘ∂ýò”–‘◊ÉÆêàD◊V°£
àD5 NUIËb∂®µƒ≤þ¬‘∫Õ¡˜≥Ã
ºº–g≤þ¬‘≈cΩM—b÷∏òÀ
| 10× Genomics de novo assembly | |
| ª˘“ÚΩMDNA | øÇ¡ø≤ªµÕ”⁄2μg£ª÷˜éߥ۔⁄50Kb£¨¥Û”⁄100Kb∏¸∫√ |
| ŒƒéÏÓê–Õ | “ªÇÄ10× GenomicsŒƒéÏ |
| úy–Úîµ(sh®¥)ì˛(j®¥)¡ø | 120GªÚ180G |
| ΩM—b÷∏òÀ | ContigN50>30Kb£ªScaffoldN50>1Mb |
Ö¢øºŒƒ´I
- Weisenfeld N I, Kumar V, Shah P, et al. Direct determination of diploid genome sequences[J]. Genome Research, 2017, 27(5):757-767.
- Hulse-Kemp A M , Maheshwari S , Stoffel K , et al. Reference quality assembly of the 3.5-Gb genome of Capsicum annuum from a single linked-read library[J]. Horticulture Research, 2018, 5(1):4.
- Liu Q , Chang S , Hartman G L , et al. Assembly and annotation of a draft genome sequence for Glycine latifolia, a perennial wild relative of soybean[J]. Plant Journal, 2018.
- Wong K H Y , Levysakin M , Kwok P Y . De novo human genome assemblies reveal spectrum of alternative haplotypes in diverse populations[J]. Nature Communications, 2018, 9(1).
- BSI—˚ƒ˙Ö¢º”µ∞∞◊Ÿ|(zh®¨)ΩMåWîµ(sh®¥)ì˛(j®¥)∑÷Œˆ≈ý”ñï˛
- ÜŒºö∞˚ø’Èg∂ýΩMåWºº–g’ìâØÙþèV÷ð’æ…˙–≈≈ý”ñ∞ýàÛ√˚÷–
- SBCÜŒºö∞˚º∞ø’Èg∂ýΩMåWåçÚû≈c…˙–≈∑÷Œˆ≈ý”ñ∞ý’–…˙
- –°∫£˝î∞l(f®°)≤º∞ŸÇÄôMœÚ’nÓ}°¢«ß∆™SCI-…˙√¸ø∆åW∫œ◊˜”ãÑù
- ø’Èg∂ýΩMåW—–æø≤þ¬‘º∞…˙–≈∑÷Œˆ≈ý”ñ∞ýªü·’–…˙÷–
- SBC ToolBox‘∆∆Ω≈_VIPå£Ö^(q®±)‘ŸÃÌ–¬ƒ£âKGSEAîµ(sh®¥)ì˛(j®¥)∑÷Œˆ
- SBC–æ‘∆÷vâØ£∫᯺“◊‘»ªø∆åWª˘Ωµƒú lj∫Õ…ÍàÛºº«…
- µ⁄ Æ∆⁄SBCÜŒºö∞˚º∞ø’ÈgÞD‰õΩMúy–Ú≈ý”ñ∞ýàÛ√˚Õ®÷™
- scMega÷˙¡¶scATAC-seqîµ(sh®¥)ì˛(j®¥)≈cscRNA-seqîµ(sh®¥)ì˛(j®¥)µƒ¬ì(li®¢n)∫œ∑÷Œˆ
- ∑«ÿìæÿÍá∑÷Ω‚NMFÀ„∑®÷˙¡¶ÜŒºö∞˚ÞD‰õΩMîµ(sh®¥)ì˛(j®¥)∑÷Œˆ
- …Ó∂»…ÒΩõ(j®©ng)æW(w®£ng)Ωj÷˙¡¶å¶ƒ[¡ˆºö∞˚Ëb∂®º∞ø’Ègê∫–‘Ö^(q®±)”Úµƒ◊RÑe
- ƒ[¡ˆºÉ∂»∫Õ±∂–‘‘uπ¿π§æþSequenzaµƒ∞≤—b∫Õ π”√∑Ω∑®
- ÜŒºö∞˚∏þºâ∑÷Œˆ∞Ÿ∆™Œƒ´IΩYπ˚’π æÖRøÇ£®¡˘£©
- ÜŒºö∞˚∏þºâ∑÷Œˆ∞Ÿ∆™Œƒ´IΩYπ˚’π æÖRøÇ£®ŒÂ£©
- π”√SBC ToolBox ÜŒºö∞˚∂∂Ñ”àDƒ£âK√¿ªØ≤ÓÆêmarkerª˘“Ú
- SBC ToolBox‘⁄Small RNA-seq∂®¡øîµ(sh®¥)ì˛(j®¥)∑÷Œˆ÷–µƒë™”√£®œ¬£©
∏¸∂ý ûg”[‘ìπ´ÀæÕ¨Óê∑˛Ñ’
ûg”[‘ìπ´ÀæÕ¨Óê∑˛Ñ’
ûg”[‘ìπ´ÀæÕ¨Óê∑˛Ñ’Copyright(C) 1998-2025 …˙ŒÔ∆˜≤ƒæW(w®£ng) Îä‘í£∫021-64166852;13621656896 E-mail£∫info@bio-equip.com